Analyzing Embedded Semantic with JSON-LD and Microdata for Educational Resources in Large Scale Web Datasets
Rosa Navarrete, Lorena Recalde, Carlos Montenegro, Sergio Luján-Mora. Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI 2019), p. 1133-1138, Las Vegas (USA), December 5-7 2019. ISBN: 978-1-7281-5584-5.
Abstract
The use of embedded markup for semantic web annotations has been fostered in the last years to produce structured information and improve visualization of search results. Its use enables major search engines to interpret and exhibit describing data from web content. This paper presents a quantitative analysis of the deployment of widely use markup formats, JSON-LD and Microdata, conducted on datasets from a large web crawling corpus of 2018. It is focusing on the use of Schema vocabulary applied to describe educational resources. The results show that Microdata largely predominates over JSON-LD encoding. This finding was not expected because Microdata is not a W3C recommendation, while, JSON-LD is such since 2014. Further, the analysis reveals a low use of Schema specific properties to describe educational resources, which could indicate a lack of interest in using markup technology in this field.
Keywords: Semantic Web, JSON-LD, Microdata, Schema.org, educational resources
More information: Analyzing Embedded Semantic with JSON-LD and Microdata for Educational Resources in Large Scale Web Datasets
- I.Introduction
- II.Background
- III.Materials and Methods
- IV.Results and Discussion
- V.Conclusions
- ACKNOWLEDGMENT
- References
I.Introduction
The embedded markup to gain structured data from the web content has become an upward trend in the semantic web because of its simplicity and the wide range of contexts in which it can be applied [1]. It is based on the inclusion of machine-readable labels within HTML code to attach semantic to specific web content [2].
These semantic annotations can be processed by main search engines to enhance the accuracy and meaningful of search results for user searches. Nowadays, search engines use embedded semantic markup to produce rich snippets, knowledge graphs, and answer blocks [3]. These enriched search results visualizations are appreciated by users to make more informed decisions of the resources they want to explore.
These semantic annotations require both, a vocabulary and an encoding format. In 2012, Schema.org became the standardized vocabulary driven by the top search engines (Google, Bing, Yahoo, and Yandex) and the World Wide Web Consortium (W3C), to produce structured data [4].
Currently, Schema vocabulary covers a wide variety of scopes, from organizations, persons, events, travel, business, industry, among others. Moreover, it is constantly evolving with the adoption of standards and vocabulary for other contexts, such as education [5]. Indeed, in 2013, it adopted the vocabulary of Learning Resource Metadata Initiative (LRMI) standard, which provides specific education-context properties [6].
Because of the importance of education as a pillar for global development [7], and considering that the Web is prevailing for publishing educational resources, it is significant to focus in this field for examining the adoption of embedded markup technology.
The Schema vocabulary is compatible with encoding formats such as Microdata and JavaScript Object Notation for Linked Data (JSON-LD). While Microdata specification has not yet been approved as a W3C recommendation [2], JSON-LD was approved as such since 2014 [8], so its adoption would be expected by the community.
Concerning educational contexts, some previous studies have found the increasing use of Microdata markup [9]–[10][11][12]. On the other hand, from the literature research, we could not find a study about the deployment of JSON-LD markup in this field.
In this work, we present a quantitative analysis of the deployment of both markup formats, Microdata and JSON-LD, in datasets extracted from large web crawling corpus released for open use in 2018. Concurrently, we analyze the use of specific Schema vocabulary to describe educational content grouped by its primary purpose (superior type, educational value, license description, and accessibility characteristics).
The results reveal a low adoption of JSON-LD, despite the sponsorship that receives as a W3C recommendation. On the other hand, Microdata is the dominant format in the datasets analyzed. Further, we found that Schema vocabulary for the educational context is not used as expected. Most of the analyzed properties have not been encountered in markup.
The remainder of this paper is structured as follows: Section II introduces the main concepts and terms for the study, Section III presents Materials and Method utilized, Section IV exposes the findings of this work and Section V presents conclusions and future work.
II.Background
A. Schema Vocabulary
Schema is currently the most extended Web vocabulary that comprises a broad range of topics. Initially, in 2011, the standard was launched with 297 classes and 187 relationships; this has increased to 638 classes and 965 relationships [5].
The purpose of Schema is to provide a vast collection of terms aimed to describe concepts and relationships in an area of concern making machine-readable definitions of commonly-used concepts[4].
The structure of Schema vocabulary is a collection of types (or “classes”), each of which has one or more parent types. Most properties can be associated with multiple classes to describe them in association with concepts. The descriptive elements that cannot be used as types are naming as terms or properties.
B. Encoding Formats
1) Microdata Format
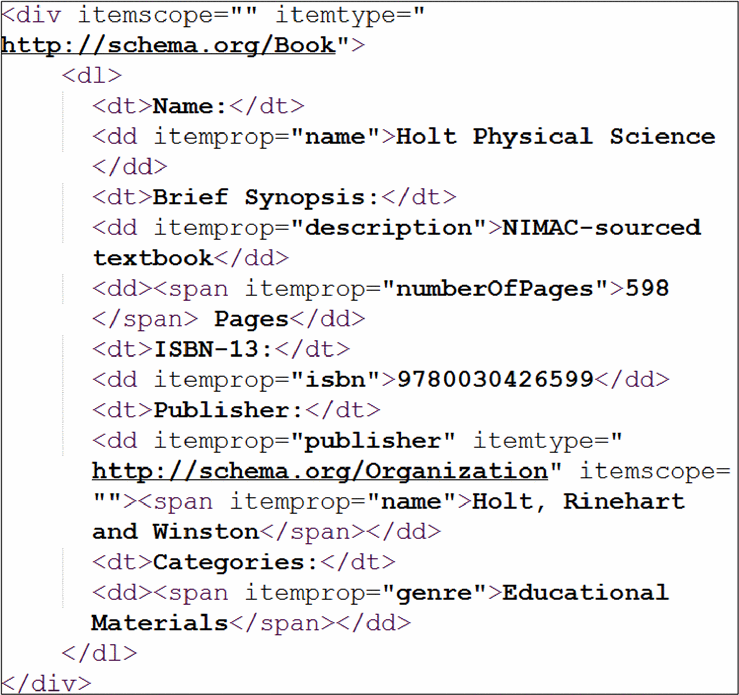
This format specification is an extension of HTML5 standardization. Microdata uses an item and name-value pairs to define values to its descriptive properties based on any supporting vocabulary [2]. Microdata markup can be added in HTML code when required by including the syntax name-value.
2) JSON-LD Format
It is the newest format to represent structured data in the embedded markup. This format places the markup in the head of the Web page, out of the HTML body, instead of being scattered in the entire document, as it occurs in other formats. JSON-LD syntax adds a script element separately from the existing markup [8].
3) Comparing Microdata and JSON-LD
Microdata markup is embedded within HTML code and can appear in any part of the web page. Instead, JSON-LD can tag in a unique block all semantic annotations making easy to write it.
One reason for embedded markup is the generation of structured data for processing within the semantic web. JSON-LD is a lightweight Linked Data format. It is separated from the HTML code, which enables its easy reading and simplifies its writing [13]. JSON-LD exposes Linked Data using the JavaScript Object Notation (JSON) [8].
Microdata extends the HTML5 markup with structured metadata. It is used to embed machine-readable data into HTML5 documents. Whereas the microdata specification describes a means of markup, the output format is JSON. It means that Microdata needs to be processed to produce structured data [2].
An example of the same annotation by using each format is presented in Figure 1 and Figure 2, respectively.

III.Materials and Methods
The description of the datasets used for analysis, Schema vocabulary to describe educational resources, and the method applied are detailed next.
A. Materials
The Common Crawl (CC) Foundation releases web corpus extracted by a crawling process in a snapshot of the most popular part of the Web defined by the PageRank strategy [14].
Datasets for analysis were obtained by the Web Data Commons (WDC) project from November 2018 web crawling corpus [15]. This was the last corpus released for public use. These datasets include only structured data produced with different encoding formats, extracted from HTML pages presented in the crawling corpus. These datasets configure a reliable sample of several million websites that semantically markup the content of their HTML pages.
Datasets are released as plain text files containing N-quads that represent a set of RDF data. Every single line in the file represents an N-quad statement. The sequence of characters in an N-quad represents a triple RDF (subject, predicate, object), followed by a label of a blank node or an IRI label (could be URI or URL) to identify the set of data from which the triple has been extracted. This sequence is terminated by a ‘.’ [1], [16]. Figure 3 depicts an example of N-quad.

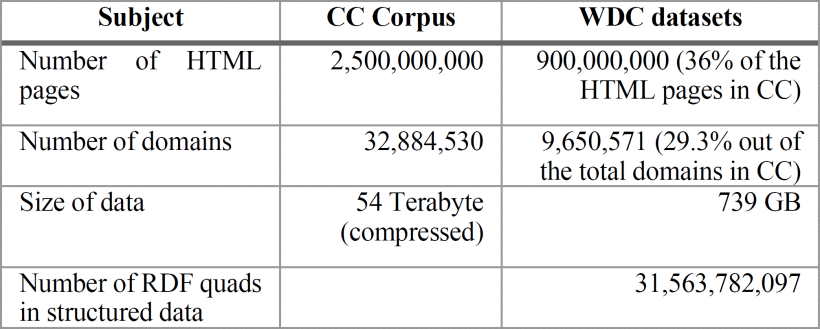
Information about the 2018 CC Corpus and WDC datasets obtained are provided in Table I. The values of datasets for each markup format are shown in Table II.

B. Schema Vocabulary for Educational Resources
We have studied the types and properties more closely pertained to concepts that describe educational content.
For the purpose of this work, the analysis verifies the use of these superior-types: CreativeWork, Book, WebPage, WebSite, Article, and Course. These are the most common kind of educational resources published on the Web.
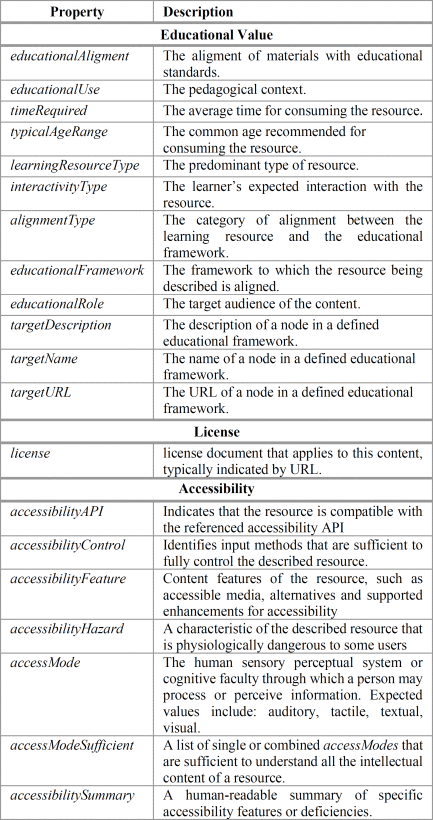
A concise description of properties is presented in Table III. These have been divided into the following groups:
- Educational, related to descriptive concepts involve with educational resources. These properties come from LRMI specification adopted for Schema.org.
- License, which describe the license for using the resource.
- Accessibility, which describes features related to control and mode required to consume the resource.
The use of superior-types and properties are not constrained for a specific sequence in the markup, so it is possible to find a sequence of the use of type/property, or the use of a type by itself.
C. Method
The analysis method is designed to respond to the following research question:
How extensive is the use of each property, in terms of N-quads and domains, for each markup format?
Datasets are formed by files with “list” extension. Each file enables the downloading of compressed files having “gz” extension. For the application of the analysis method, datasets have been downloaded to enable local processing.
For the compute-intensive task required for analysis, we chose Phyton as the programming language to execute all the method steps, including the results report. Phyton is one of the most used scripting languages, particularly for data analysis tasks, because of its flexibility, simplicity, and productivity [16]. The steps for the analysis method were:
- Decompress each file on the list and download it for local processing.
- Open the file and process each N-quad statement to extract its components.
- Verify if the structure of the N-quad statement is correct. It must present the four components, include only accepted characters into each component, use a blank space to separate each component from others, and close the sentence with a period. If the N-quad does not comply with these mandatory rules (for example, escape characters are found in the middle of the elements, or blanks in the middle of the URL, etc.), it is not considered for evaluation because it could be not correctly processed.
- Separate the N-quads considered erroneous. These are reported as “non-processable N-quad”.
- Isolate the sequence of “superior-type/property” involved in the predicate component of the analyzed N-quad statement. We compare the term in the predicate with the set of superior-types and properties of the Schema vocabulary selected for this work. If any of these terms are found, the N-quad statement is separated for the next step of the analysis. This step considers the structure of the N-quad statement, “subject predicate object URL” (each component separated with a blank).
-
Group and prepare statistics of the use of “superior-type/property” or only “type”. An example of these choices is presented below:
superior-type/property https://schema.org/CreativeWork/educationalUse
superior-type https://schema.org/CreativeWork - Group the N-quads by domain. We assume that the analyzed properties, particularly those that come from LRMI specification, are mostly related to educational domains, and their use has pertained for educational resources.
IV.Results and Discussion
Datasets for analysis were extracted from the same web corpus. Based on the values detailed in Table II, the dataset containing JSON-LD N-quads represents only 21.23% concerning the dataset containing Microdata N-quads. Hence, it is clear to observe the preference for Microdata as encoding for embedded markup.
The analysis conducted in this work verified, for each markup format, the number of N-quads detected for only “superior-type” markup (no property specified) and “superior-type/property” markup. The analysis covered only the superior-types and properties detailed in Section III, literal B, Schema vocabulary for educational resources. The results are exposed below.
A. JSON-LD Results
The total N-quads encountered in the dataset for JSON-LD markup are 4,223,740,670 (see Table II). From this total N-quads, the number of N-quads detected with the set of superior-types and properties analyzed in this work is 49,445,248. It means 1.17% of the entire dataset.
Table IV shows the number of N-quads detected using only “superior-type” in the markup and the percentage with respect to the number of n-quads.
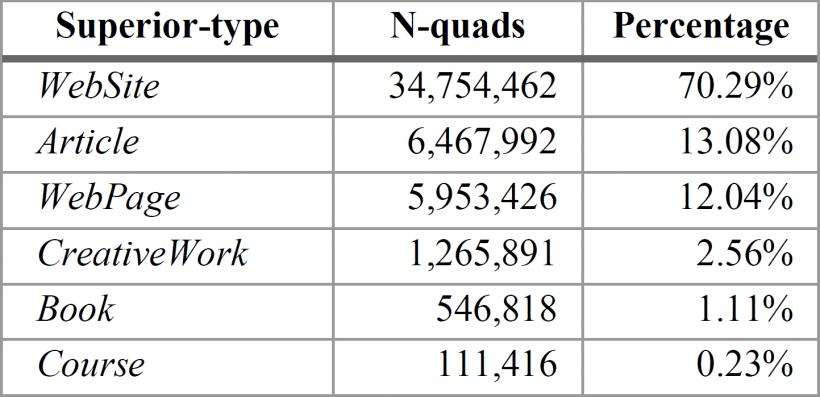
Table V shows the number of N-quads detected using the “property” in the markup (combined with a superior-type not included in this study or alone) and the percentage with respect to the number of n-quads.
For JSON-LD, we did not find the use of “superior-type/property” in the set analyzed. Besides, it was not found the markup with any property of accessibility and only five properties of the LRMI set. The license property was detected with a low number of N-quads.
The predominant “superior-type” with 70.29% has been “WebSite”. Considering this fact, it would be expected that some of these websites were related to educational purposes; nevertheless, the findings demonstrated the opposite. The use of properties from the Educational Value group is not representative at all, less than 1%.
In summary, the choice of JSON-LD encoding for markup is still limited, particularly for the educational context.
B. Microdata Results
The total N-quads encountered in the dataset for Microdata markup are 19,891,019,918 (see Table II). From this total N-quads, the number of N-quads detected with the set of types and properties analyzed in this work is 334,648,706. It represents 1.68% of the entire dataset.
Table VI shows the number of N-quads detected using only “superior-type” in the markup and the percentage with respect to the number of N-quads.

Table VII shows the number of N-quads detected using the “property” in the markup (combined with a superior-type not included in this study or alone) and the percentage with respect to the number of n-quads.
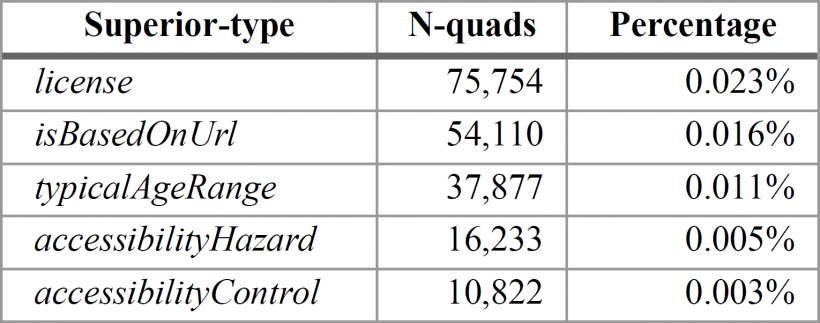
Table VIII shows the use of “superior-type/property” for the set defined for this study. The properties that do not appear in this table were not used in this way of markup.
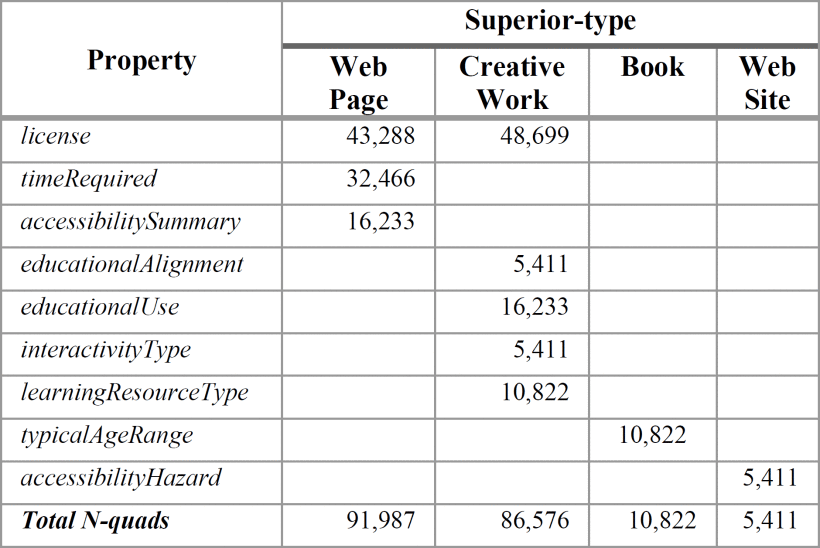
The total number of N-quads marked with “superior-type/property” concerning the set of types and properties analyzed is 194,796.
Figure 4 presents the percentage of N-quads with a “superior-type/property” markup.
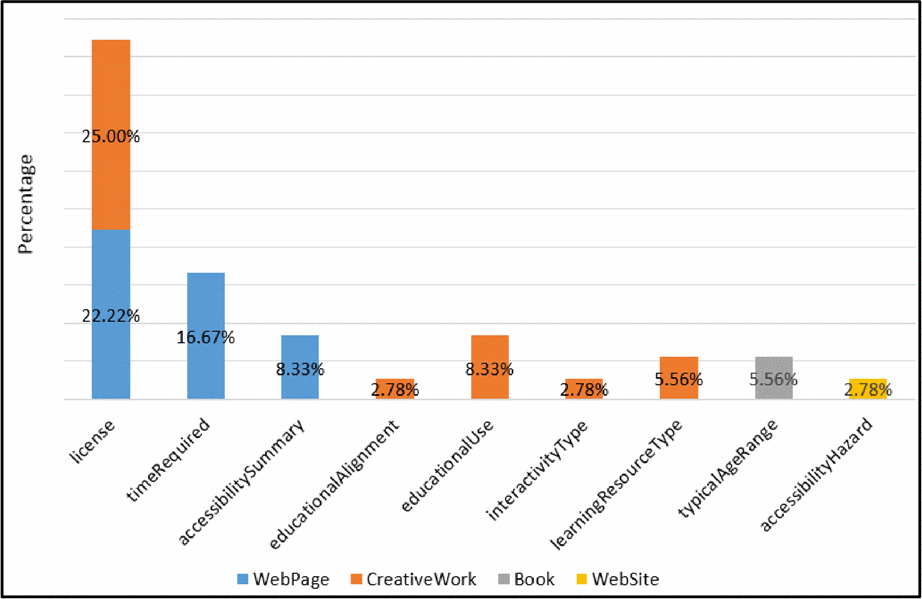
The most used “superior-type” has been Article, with 48.45% over WebPage with 25.29%, and CreativeWork with 15.2%. However, WebSite appears only with 6.2%. It is visible that people who publish on the Web choose the encoding format they prefer.
Four accessibility properties have been used in Microdata markup. It means that who publish web content have awareness about accessibility issues. These properties are mainly used with WebPage and WebSite. The license properties have been used with WebPage and CreativeWork, which is a common practice for describing the conditions of use of the resource.
Although Microdata is still the preferred encoding format for embedded markup, its use regarding educational context is not a generalized practice for publishing content on the Web.
C. Domains
Due to the lack of space, the results regarding domains only show the most representative domains related to the educational context. The results are presented according to each type of format, and the number of N-quads detected are reported, as well.
JSON-LD The analysis determined 8,923 unique domains. The domain www.flickr.com had the highest number of N-quads, with 288,069. This domain is an application to manage and distribute online photographs and images.
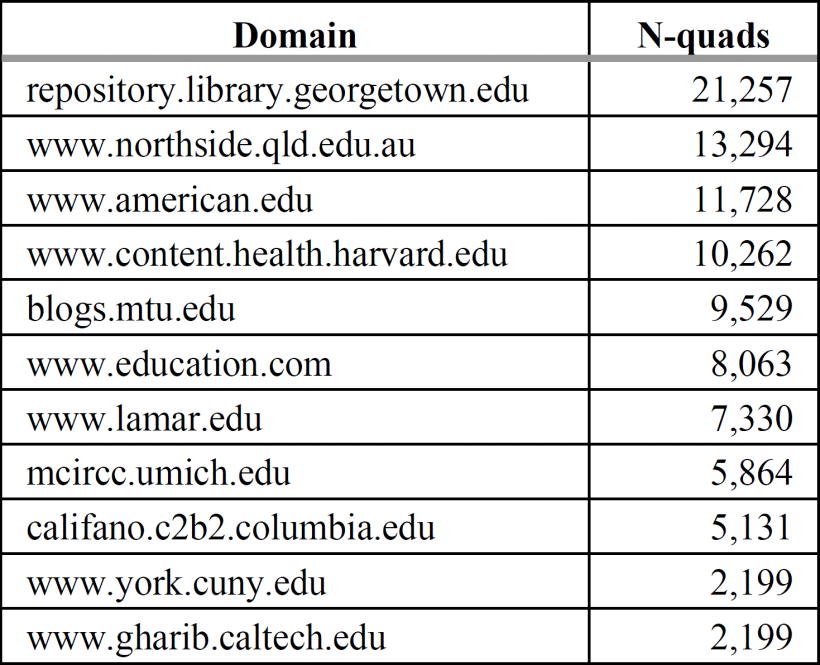
Only 23 domains were found concerning the educational context. It means 0,26% of the total number of domains. The top 10 educational domains, based on the number of N-quads detected, are exposed in Table IX.
Microdata The number of unique domains encountered for this encoding format is 16,044. The domain with the highest number of N-quads was www.sustainableoilfield.com with 5,681,550.
Only 98 domains were detected for the educational context, which represents 0.61% of the total number of domains. The top 10 educational domains, based on the number of N-quads detected, are exposed in Table X.
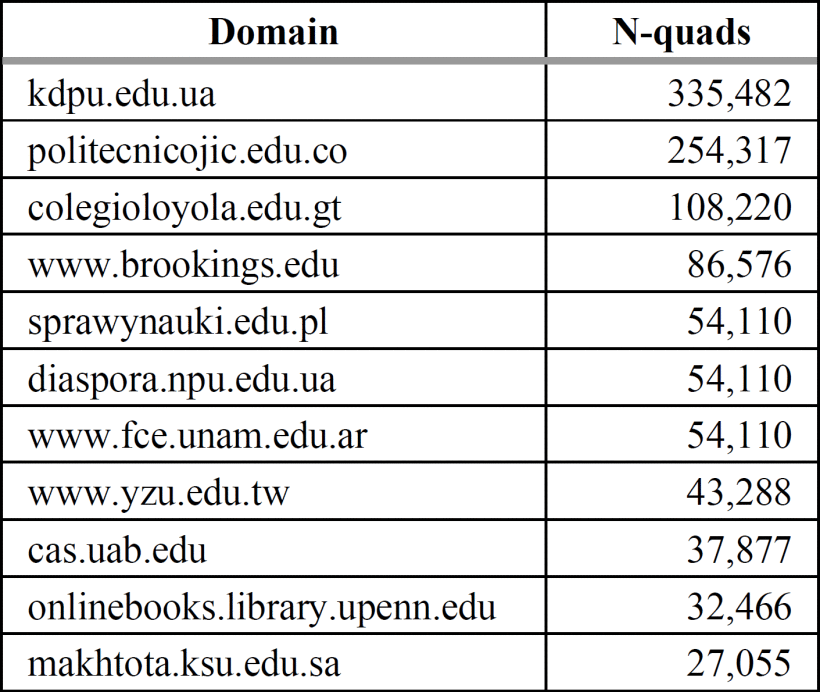
As shown in Tables IX and X, the number of N-quads for each domain identified in the educational context is significantly higher in domains detected with Microdata encoding markup than JSON-LD encoding markup.
V.Conclusions
This work has explored large-scale datasets of structured data coming from a web crawling corpus. The aim of this research work was to determine which is the extension in the deployment of the encoding formats JSON-LD and Microdata for embedded semantic.
Based on the results, we can argue that Microdata continues as the preferred format over JSON-LD. Although JSON-LD is a W3C recommendation, its adoption by the community is quite low.
Concerning the educational context, the exploration determined a low use of the superior-types and properties examined. It is possible to argue that the embedded semantic markup is a hardly exploited technology in the educational context, despite its potential to increase the richness in the web search results.
Further, the appropriate use of embedded markup of educational resources requires an understanding of the Schema vocabulary terms. The misuse of terms is observed since their interpretation varies. Consequently, some properties applied in contexts not related to education have been found, for instance, educationalUse and typicalAgeRange.
On the other hand, the web crawling corpus covers only a subset of all webpages and it is not specifically oriented to predefined areas of interest. Thus, to conduct a more reliable analysis of the actual deployment of the markup formats in the educational context, our future work aims to analyze a corpus obtained from scraping targeted at main educational websites. In datasets obtained from this corpus, we would deeply analyze the trend in the use of Schema vocabulary, considering all combinations of superior-types and properties.
ACKNOWLEDGMENT
This work is financed with funds from the PII-18-01 research project from Escuela Politécnica Nacional.
References
1. R. Meusel, R. Petrovski, P., Y Bizer, C, C. Bizer, "The webdatacommons microdata RDFa and microformat dataset series", 13th International Semantic Web Conference (ISWC 2014), 2014.
2. "HTML Microdata W3C Working Draft", W3C, April 2018, [online] Available: https://www.w3.org/TR/microdata/.
3. O. Panasiuk, O. Holzknecht, U. Şimşek, E. Kärle, D. Fensel, "Verification and Validation of Semantic Annotations", Computing Research Repository, vol. abs/1904.01353, 2019.
4. Schema.org, 2016, [online] Available: http://schema.org/.
5. R. V. Guja, D. Brickley, S. Macbeth, "Schema. org: Evolution of structured data on the Web", Communications of the ACM, vol. 59, no. 2, pp. 44-51, 2016.
6. LRMI Version 1.1, 2014, [online] Available: http://lrmi.dublincore.net/lrmi-1-1/.
7. World Education Forum Final Report, 2015.
8. JSON-LD 1.0, 2014, [online] Available: https://www.w3.org/TR/json-ld/.
9. D. Taibi, S. Dietze, "Towards Embedded Markup of Learning Resources on the Web: An Initial Quantitative Analysis of LRMI Terms Usage", Proceedings of the 25th International Conference Companion on World Wide Web, 2016.
10. P. Sahoo, U. Gadiraju, R. Yu, S. Saha, S. Dietze, "Analysing Structured Scholarly Data Embedded in Web Pages", Semantics Analytics Visualization. Enhancing Scholarly Data: Second International Workshop SAVE-SD 2016, 2016.
11. S. Pohorec, M. Zorman, P. Kokol, "Analysis of approaches to structured data on the web", Computer Standards & Interfaces, vol. 36, no. 1, pp. 256-262, 2013.
12. R. Navarrete, S. Luján-Mora, "A Quantitative Analysis of the use of Microdata for semantic annotations on Educational Resources", Journal of Web Engineering, vol. 17, no. 1&2, pp. 45-72, 2018.
13. F. Sikos, LF Sikos, Mastering Structured Data on the Semantic Web: From HTML5 Microdata to Linked Open Data, Apress, 2015.
14. Common Crawl, 2016, [online] Available: http://commoncrawl.org/.
15. Web Data Commons - RDFa Microdata and Microformat Data Sets, 2019, [online] Available: http://webdatacommons.org/structureddata/.
16. RDF 1.1 N-Quads, 2016, [online] Available: https://www.w3.org/TR/n-quads/.
17. C. Ozgur, T. Colliau, G. Rogers, Z. S. Hughes, B. Myer-Tyson, "Matlab vs. Phyton vs. R", Journal of Data Science, vol. 15, no. 3, 2017.
18. HTML Microdata, 2018, [online] Available: https://www.w3.org/TR/microdata/.
More information: Analyzing Embedded Semantic with JSON-LD and Microdata for Educational Resources in Large Scale Web Datasets