El juego de caracteres
La codificación de caracteres es el método que convierte un carácter de un lenguaje natural en un símbolo de otro sistema de representación, como un número o en el caso de un ordenador una secuencia de unos y ceros. El juego de caracteres es la equivalencia carácter a carácter de la codificación de los caracteres de un lenguaje natural a un sistema de representación.
El juego de caracteres es la pesadilla de cualquier informático. Desgraciadamente, es un problema que heredamos desde los orígenes de los ordenadores y que parece que no nos lo vamos a poder quitar de encima… Por ejemplo, en la siguiente figura podemos ver lo que ocurre cuando se recibe un correo electrónico y el juego de caracteres utilizado o indicado en el correo no es el correcto.

Durante muchos años, el juego de caracteres más extendido era ASCII. En ASCII, a cada carácter se le asigna un número del 0 al 127 (7 bits). ASCII sólo permite 128 caracteres diferentes, suficientes para el inglés, pero no incluye ni la eñe, ni las vocales acentuadas ni el comienzo de interrogación o exclamación que se usa en castellano, ni símbolos (matemáticos, letras griegas...) que son necesarios en muchos contextos.
En la siguiente figura se muestra la tabla de caracteres ASCII incluida en el manual de un terminal del año 1972. Para calcular el código en decimal de un carácter se debe multiplicar por 16 el valor indicado en "Column" y sumar el valor indicado en "Row". Por ejemplo, la letra "A" mayúscula es 4x16 + 1 = 65, mientras que la letra "a" minúscula es 6x16 + 1 = 97.
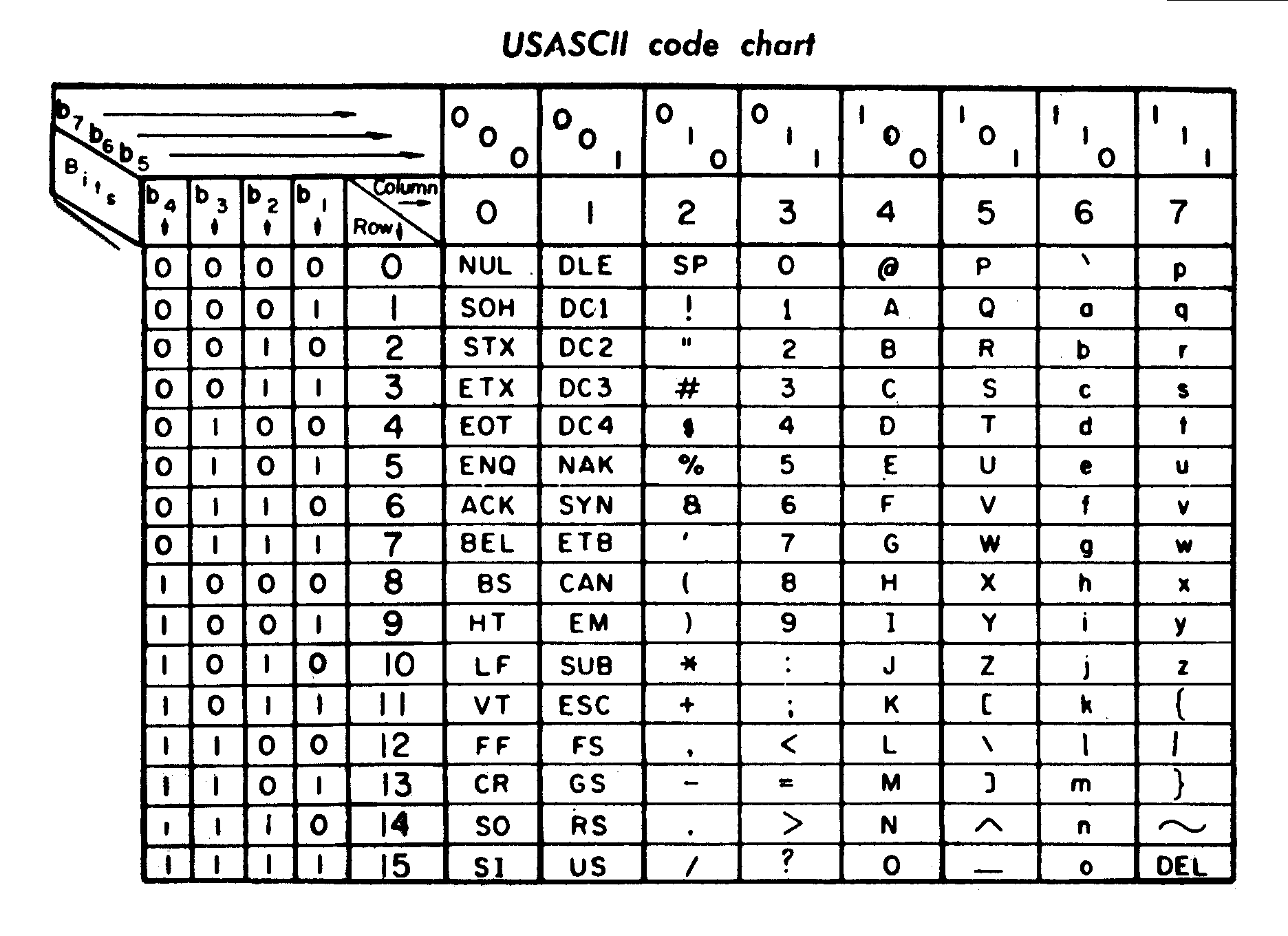
Fuente: Wikipedia, File:ASCII Code Chart-Quick ref card.png
{kind=link}
El juego de caracteres ASCII extendido de 256 caracteres (8 bits) permite representar caracteres no ingleses como las vocales acentuadas o la eñe. Los caracteres de la parte superior (128 a 255) del ASCII extendido varían entre distintos juegos de caracteres. Por ejemplo, el ISO Latin-1 (oficialmente ISO 8859-1), es el empleado en España, ya que contiene las vocales acentuadas y la eñe. Este juego de caracteres también es el que normalmente se emplea en los países de Europa occidental. Sin embargo, ISO 8859-1 no es capaz de representar todos los caracteres y símbolos que se puedan necesitar en diferentes países, por lo que existen diferentes variantes tal como se puede observar en la siguiente figura que muestra un fragmento de las diferencias que existen entre las variantes ISO 8859-1 e ISO 8859-16 (la variante ISO 8859-12 fue abandonada).
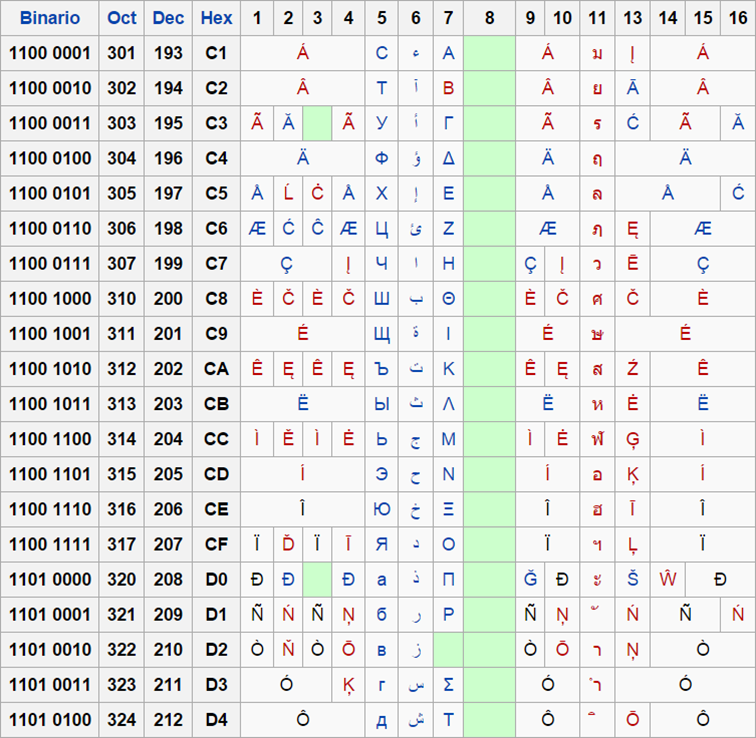
En esta tabla se pueden apreciar estas diferencias entre los diferentes juegos de caracteres. Algunos ejemplos de estas diferencias son:
- En los juegos de caracteres ISO 8859-1 (Europa occidental), 8859-2 (Europa occidental y Centroeuropa), 8859-3 (Europa occidental y Europa del sur) y 8859-4 (Europa occidental y países bálticos) el código decimal 201 representa el carácter “É”, mientras que en ISO 8859-5 (Alfabeto cirílico) eso mismo código representa el carácter “Щ”.
- En el juego de caracteres ISO 8859-1 el código decimal 209 representa el carácter “Ñ”, en ISO 8859-2 el carácter “Ń”, en ISO 8859-2 el carácter “Ñ”, en ISO 8859-1 el carácter “Ņ” y en ISO 8859-1 el carácter “б”.
En la actualidad se recomienda utilizar Unicode en las páginas web. Unicode es un estándar diseñado para facilitar el tratamiento informático, la transmisión y la visualización de textos escritos en múltiples lenguajes.
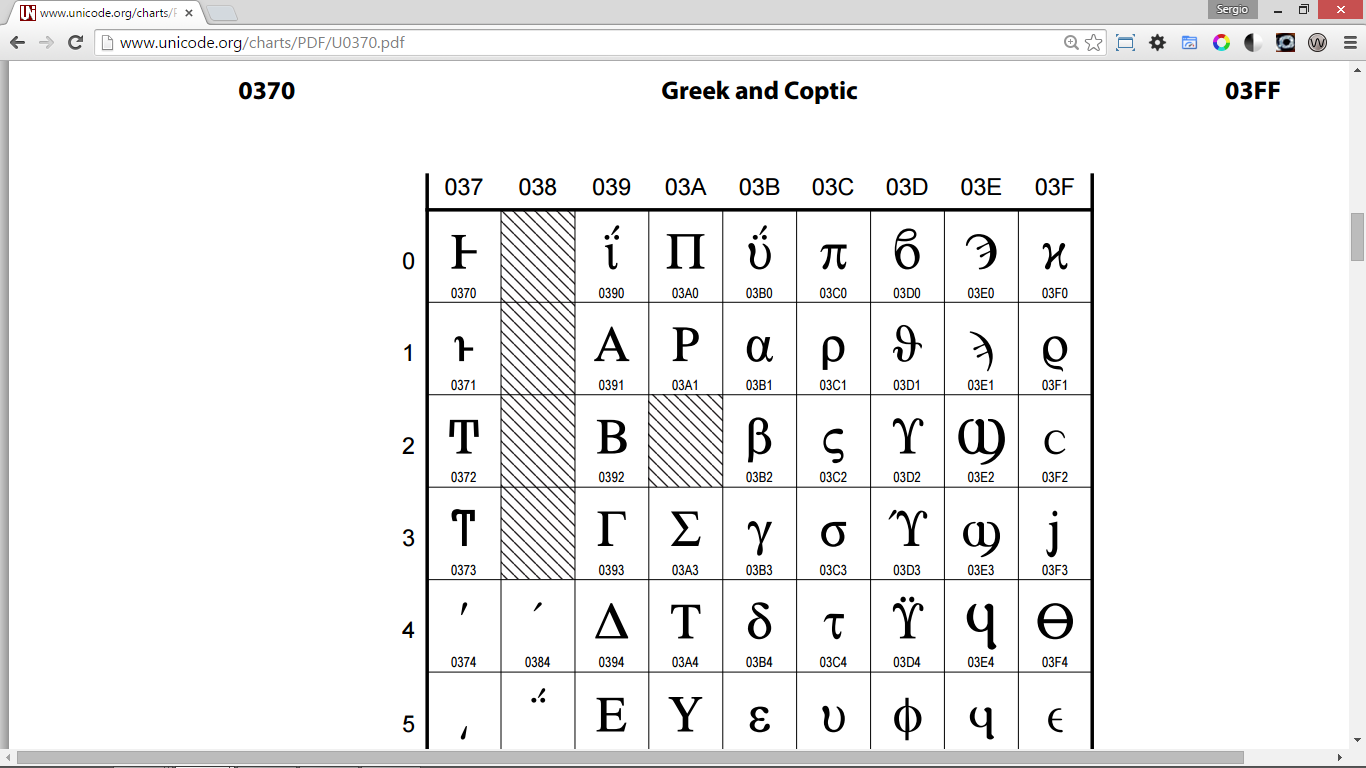
En el sitio web oficial de Unicode podemos encontrar las Character Code Charts en las que se detallan todos los caracteres incluidos en la especificación de Unicode.
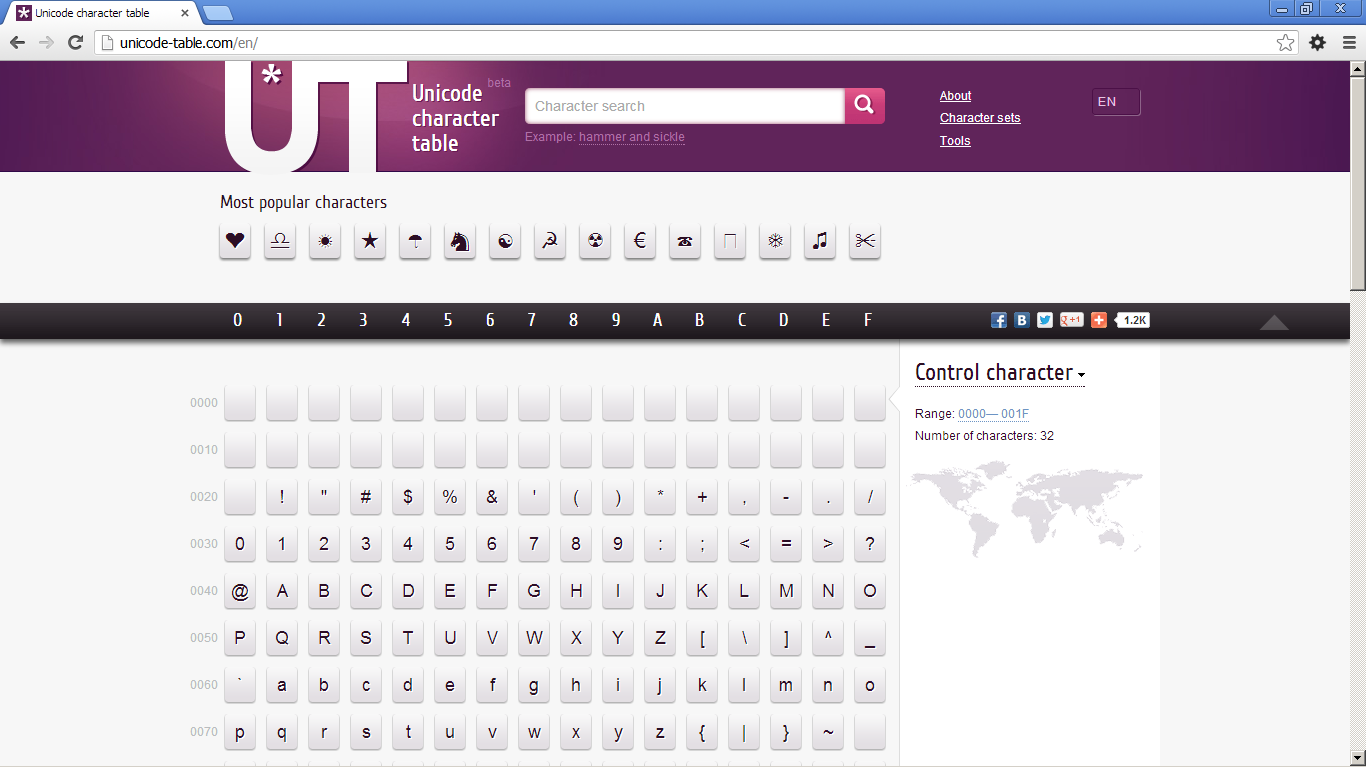
Estas tablas no son cómodas de manejar cuando se busca un carácter concreto porque está organizada por idiomas. En Unicode character table han juntado todos los caracteres en una sola tabla.
El W3C en su documento Internationalization Techniques: Authoring HTML & CSS recomienda el empleo de Unicode mediante UTF-8 (RFC 3629 UTF-8, a transformation format of ISO 10646), un formato de codificación de los caracteres Unicode utilizando símbolos de longitud variable. Las características principales de UTF-8 son:
- Es capaz de representar cualquier carácter Unicode.
- Usa símbolos de longitud variable (de 1 a 4 bytes).
- Incluye la especificación ASCII de 7 bits, por lo que cualquier cadena de texto ASCII se representa sin cambios en UTF-8.
La comunidad de desarrolladores web WHATWG también recomienda el uso de UTF-8 en su documento Encoding. Según este documento, UTF-8 se puede representar con las siguientes etiquetas:
- unicode-1-1-utf-8
- utf-8
- utf8
El juego de caracteres de una página web se puede indicar de varias formas. A nivel de servidor, se puede enviar un encabezado HTTP indicando el juego de caracteres:
Content-Type: text/css; charset=UTF-8
Sin embargo, lo normal es indicar el juego de caracteres a nivel de página web mediante la etiqueta <meta>.
En versiones anteriores de HTML se empleaba la siguiente notación:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html lang="es"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
En HTML5 se puede emplear esta notación simplificada:
<!DOCTYPE html> <html lang="es"> <head> <meta charset="utf-8" />
¡MUY IMPORTANTE!: el juego de caracteres que se defina con la etiqueta <meta> debe ser el mismo juego de caracteres que se utilice al guardar la página web desde el editor de textos.
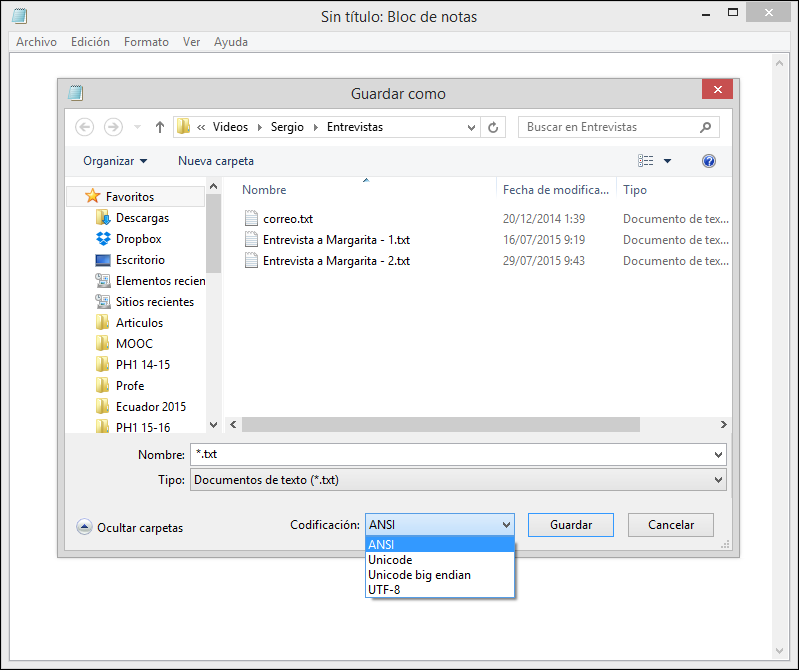
Por ejemplo, en el editor de textos Bloc de notas de Microsoft Windows, cuando se guarda un fichero por primera vez aparece la lista desplegable "Codificación", tal como se puede ver en la siguiente imagen:
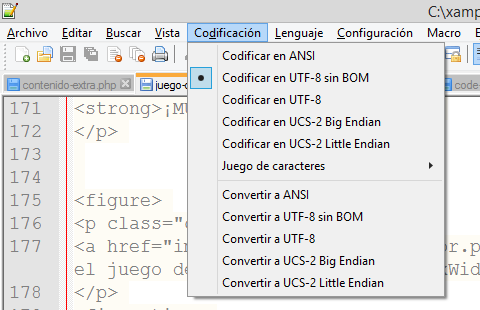
En el editor de textos Notepad++ existe el menú "Codificación", tal como se puede ver en la siguiente imagen:
Además, en Notepad++ se indica la codificación del documento actual en la barra de estado:

UTF-8 es un formato de codificación de los caracteres de longitud variable, lo que significa que los caracteres no se representan siempre con un mismo número de bytes. Por ejemplo, los caracteres:
A ≢ Α .
que se lee como:
A (a mayúsculas) no es idéntico a Α (alpha mayúsculas) punto
se representa con la secuencia de caracteres Unicode U+0041 U+2262 U+0391 U+002E, que se codifica en UTF-8 como (los valores están expresados en hexadecimal):
--+--------+-----+-- 41 E2 89 A2 CE 91 2E --+--------+-----+--
La letra A se representa con 1 byte (41), el símbolo ≢ con 3 bytes (E2 89 A2), la letra Α con 2 bytes (CE 91) y el punto con 1 byte (2E).
Aunque Unicode y sus representaciones como UTF-8 son la solución a todos los problemas, a veces no se pueden emplear porque se trabaja con un sistema heredado que no lo soporta. En esos casos hay que usar un juego de caracteres específico como ISO 8859 con sus diferentes versiones y variantes. Según WHATWG, ISO-8859-1 se compone de estos caracteres y se puede representar con las siguientes etiquetas:
- ansi_x3.4-1968
- ascii
- cp1252
- cp819
- csisolatin1
- ibm819
- iso-8859-1
- iso-ir-100
- iso8859-1
- iso88591
- iso_8859-1
- iso_8859-1:1987
- l1
- latin1
- us-ascii
- windows-1252
- x-cp1252
En HTML existen cuatro formas de incluir un carácter Unicode en una página web:
- Se puede escribir directamente a través del teclado o se puede copiar de otro documento.
- Se puede escribir mediante una entidad HTML. La lista de entidades HTML ha aumentado considerablemente de la versión HTML4 (Character entity references in HTML 4) a la versión HTML5 (Character Entity Reference Chart).
- Se puede escribir el código Unicode decimal como &#dddd;.
- Se puede escribir el código Unicode hexadecimal como &#xhhhh;.
Por tanto, en el ejemplo anterior, los caracteres A ≢ Α . que se representan con la secuencia de caracteres Unicode U+0041 U+2262 U+0391 U+002E se pueden escribir en HTML como:
A ≢ Α .
En la siguiente tabla se representan las cuatro formas de representar los cuatro símbolos de una baraja francesa (picas, tréboles, corazones y diamantes):
| Carácter | Entidad | Decimal | Hexadecimal |
|---|---|---|---|
| ♠ | ♠ | 9824 | 2660 |
| ♣ | ♣ | 9827 | 2663 |
| ♥ | ♥ | 9829 | 2665 |
| ♦ | ♦ | 9830 | 2666 |
Si necesitas más información, consulta los siguientes vídeos:
HTML: juego de caracteres
Ejemplos reales de problemas con el juego de caracteres, consejos más importantes: utiliza siempre el mismo juego de caracteres, utiliza UTF-8 sin BOM, diferencias entre ISO-8859-1 (Latin1) e ISO-8859-15 (Latin9), cómo se indica el juego de caracteres en HTML (etiqueta meta), diferencias entre HTML4, XHTML1 y HTML5.
HTML: el juego de caracteres y los editores de texto
UTF-8 sin BOM (Byte Order Mark), ¿qué es el BOM? Típicos problemas con los editores de texto.
HTML: ¿migrar a un nuevo juego de caracteres?
¿Qué pasa si ya tenemos un sitio web con otro juego de caracteres? ¿Debemos migrar a UTF-8 sin BOM?